一、缓存如何实现高性能和高并发的?
当系统用户量增大时,必然其业务量和访问就会增加,对于数据库(如MySQL)来说其连接数量是有上限(单个也就几千左右);
在其达到数据库瓶颈后,此时响应速度自然会变慢,最终导致积压大量的请求在系统中,最后数据库抗不住了直接崩溃,导致整个系统无法正常提供服务。
为了解决这个问题由此引入缓存,即将数据缓存在内存中,每次如果查询条件一样就直接从缓存里面获取返回;因为缓存是放在内存中的,而内存是天然就支持高并发的。
二、缓存的常见问题?
我们引入缓存后自然也就会引发新的问题,下面是一些常见的问题。
缓存穿透
在高并发的情况下某个key被频繁访问,但是实际上数据库里面是没有的,缓存里面也就没有,这就导致每次都去访问数据库;
或者是每次访问的key在缓存里面都没有,这样也就导致每次都去访问数据库;这就是缓存穿透,即每次访问都没有命中缓存。
这情况下如果系统未做限流那么就很可能将数据库直接弄崩溃,从而导致整个系统无法提供正常的服务。解决方案:
- 对于查询结果是空数据的情况,可以将空数据缓存下来,这里避免频繁的去访问数据库;
- 如果有人恶意构造不同的key,导致每次都去访问数据库;这种我们可以加入限流的拦截;
- 对请参数做限制,不要什么都接收;如果是那种更新不频繁的且key几乎固定的,我们可以去那些无效key直接过滤掉;
缓存颠簸问题
缓存颠簸也叫缓存抖动,一般是由于缓存节点故障导致。业内推荐的做法是通过一致性Hash算法来解决。
缓存雪崩
缓存雪崩就是指由于缓存的原因,导致大量请求到达后端数据库,从而导致数据库崩溃,整个系统崩溃,发生灾难。简单来说就缓存没法干活了,直接就去访问数据库了。
出现缓存雪崩的情况:1.由于设置的缓存失效时间基本相同,某段时期缓存同时失效,导致直接请求数据库;2.缓存组件直接被干掉了,比如Redis都被干掉了,通常是没有做限流导致的;
3.缓存穿透导致的。解决方案:
- 设置的缓存失效时间尽量不要弄成一样的,防止缓存在同一时间失效;
- 对缓存key做处理,比如限制参数信息、空结果也缓存、key值限制;
- 系统构架上应当考虑做限流、降级、熔断机制,这种突发情况对系统的影响;(比如做了限流,虽然用户可能会遇到无法访问的问题,但是至少还是有部分用户能够成功进入系统进行操作);
- 增加多级缓存来增强系统的抗压能力。
- 提前进行缓存预热;即提前将热点数据先缓存起来。
缓存并发问题
就是在刚开始的时候缓存里面都没有数据,在高并发的情况下,都去查询数据库然后更新到缓存里面最后返回结果,由于有很多个都在干这个事情因此可能出现数据不一致的问题;
同时在这种情况下也可能导致缓存雪崩问题。那么如何避免呢?可以通过加锁(即牺牲一些时间和性能)来解决。
缓存一致性
当数据时效性要求很高时,需要保证缓存中的数据与数据库中的保持一致;而且为了保存缓存的高可用通常会使用副本机制,因此还需要保证缓存节点和副本中的数据也保持一致,不能出现差异现象。
这就比较依赖缓存的过期和更新策略。一般会在数据发生更改的时,主动更新缓存中的数据或者移除对应的缓存。
下面的这种情况,在并发高时不论你是先更新数据库还是先处理缓存都会出现缓存一致性问题。
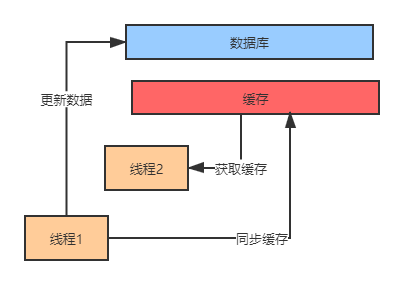
缓存一致性问题的解决方案:
数据实时同步更新;
- 技术特点:强一致性,更新数据库同时更新缓存;依然可能出现数据一致性的问题;
- 优点:数据一致性强,不会出现缓存雪崩问题;
- 缺点:代码耦合、运行期耦合、影响正常业务、增加网络开销;
- 适用场景:适合写操作频繁的细粒度缓存数据,数据一致实时性要求较高的场景,如银行、证券;
数据准实时更新
- 技术特点:准一致性,更新数据库后,异步更新缓存。基于多线程、队列或MQ实现;
- 优点:数据同步有较短延迟、与业务解耦、不影响正常业务,不会出现缓存雪崩问题;
- 缺点:无法保证最终一致性,需要补偿机制;
- 适用场景:不适合写操作频繁且数据一致实时性要求严格的场景;
缓存失效机制
- 技术特点:弱一致性,靠缓存淘汰机制实现简单。
- 优点:简单,不影响正常业务;
- 缺点:有一定延迟,存在缓存雪崩问题,因此在设置缓存时间时尽量设置成不一样的值,减少缓存雪崩。
- 适用场景:适合读多写少的互联网场景,能接受一定数据延时。如电商、理财、社交类业务
任务调度更新
- 技术特点:最终一致性,采用任务调度框架,按一定频率更新
- 优点:不影响正常业务
- 缺点:不保证一致性,代码复杂度增大,容易堆积垃圾数据
- 适用场景:适合复杂统计类数据缓存更新,对数据一致实时性要求低的场景。
目前很多都使用的是缓存失效机制。




